






Data Warehousing and Data Mining
This course introduces advanced aspects of data warehousing and data mining, encompassing the principles, research results and commercial application of the current technologies.

Tribhuvan University
Institute of Science and Technology
2080
Bachelor Level / seventh-semester / Science
Computer Science and Information Technology( CSC410 )
Data Warehousing and Data Mining
Full Marks: 60 + 20 + 20
Pass Marks: 24 + 8 + 8
Time: 3 Hours
Candidates are required to give their answers in their own words as far as practicable.
The figures in the margin indicate full marks.
SECTION A
Attempt any TWO questions.
State Apriori property. Find frequent item sets and association rules from the transaction database given below using Apriori algorithm. Assume min. support is 50% and min confidence is 75%.
| Transaction ID | Items Purchased |
| 1 | Bread, Cheese, Egg, Juice |
| 2 | Bread, Cheese, Juice |
| 3 | Bread, Milk, Yogurt |
| 4 | Bread, Juice, Milk |
| 5 | Cheese, Juice, Milk |
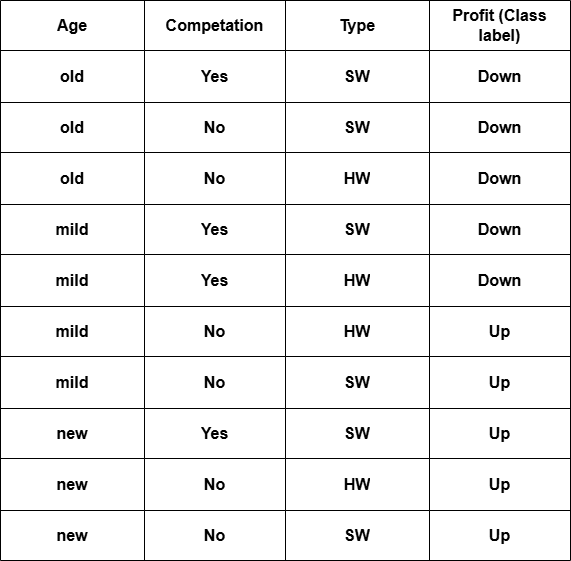
How classification differs from regression. Train ID3 classifierusing the dataset given below. Then predict class label for the data [Age=Mid, Competition=Yes, Type=HW].
Why the concept of data mart is important? Discuss different data warehouse schema with examples.
SECTION B
Attempt any EIGHT questions.
How KDD differs from data mining? Explain various stages of KDD with suitable block diagram.
Discuss different ways of smoothing noisy data along with suitable examples.
How many cuboids are possible from 5-dimensional data? Discuss the concept of full cube and iceberg cube.
How K-medoids clustering differs from K-means clustering? Divide the following data points into two clusters using kmedoids algorithm. Show computation up to 3 iterations. {(70,85), (65,80), (72,88), (75,90), (60,50), (64,55), (62,52), (63,58)}.
Discuss working of DBSCAN algorithm.
Which algorithm is used for training multi-layer perceptron? Discuss the algorithm in detail.
Explain the OLAP operations with examples.
Discuss the concept of multimedia data mining along with the concept of similarity search.
Write down short notes on:
- Support Vector Machine
- Multi-dimensional Data Model